Harness Engineering
Harness Engineering 驾驭工程,指的是在一个 Agent 系统中,除了模型本身以外几乎所有决定它能不能稳定交付的东西。其核心目标是解决 AI Agent 在真实场景中的执行稳定性问题,确保模型能够从 "能思考" 到 "能稳定做事" 的关键跨越
AI 工程的演变
Prompt Engineering
Prompt Engineering 的核心是让模型听懂你在说什么,通过设计巧妙的提示语来引导模型生成符合预期的输出。重点在于角色设定、风格约束和示例引导等方法
例如:
帮我总结这篇文章请以资深技术编辑的身份,用三段结构总结这篇文章,先讲核心观点,再讲论证方式,最后讲局限性,每段不超过 150 字重要
之所以 Prompt Engineering 能够在短期内大幅提升模型输出质量,是因为大模型本质上是一个对上下文非常敏感的概率生成系统。你给它什么身份它就会沿着那个身份去回答,给它什么示例它就会沿着那个示例的格式去输出,强调什么样的约束它就更容易把那部分作为重点
Prompt Engineering 的本质不是 "命令模型" 而是塑造一个局部概率空间
Prompt Engineering 虽然能够在一定程度上优化模型的表达,但无法弥补知识缺失,也不擅长管理动态信息
Context Engineering
Prompt Engineering 适合任务短、链路少的场景,很多问题确实依靠把提示词设计好就可以解决。但是后续随着任务复杂度增加,模型进到真实的环境中执行任务,可能要进行多轮对话、调用浏览器、写代码等等
那这个时候系统面对的已经不是一次回答对不对,而是整条链路能否跑通
分析需求文档 -> 找出潜在风险 -> 结合历史意见 -> 生成反馈稿这已经不是单靠提示词就能解决的问题,因此 Context Engineering 的核心就是模型未必知道全部信息,系统必须在合适的时机把正确的信息提供给模型。因此成熟的 Context Engineering 是需要按需给、分层给、在正确时机给予模型的
信息
Context 表示的所有会影响模型当前决策的信息总和,因此 Prompt 也是 Context 的一部分
Harness Engineering
那即便有了 Context Engineering 模型也不一定能够稳定执行。例如,模型可能在某一步因为信息不全或者误解了上下文而做出错误决策,导致整个链路崩溃;或者模型虽然知道要调用工具,但不知道怎么调用;又或者模型在多步骤任务中前面做对了,后面因为状态丢失或者流程管理不善而越走越偏
那这个时候就发现,Prompt Engineering 是优化意图的表达,Context Engineering 是优化信息的供给,它们都是在模型的输入端做文章。但是当模型在一个复杂的场景中开始连续工作时,谁来监督、约束、纠正它的行为
这就是 Harness Engineering 主要解决的问题:确保模型在真实执行里,能持续做对这件事

Harness 架构
上下文管理
Harness 的第一层职责,是让模型在边界内思考。这一层通常包括:
- 角色和目标定义:让模型知道自己是谁、任务是什么、成功标准是什么
- 信息的裁剪和选择:根据当前任务阶段和需求,动态地选择和组织输入模型的信息,避免信息过载或者信息不足
- 结构化组织:固定的规则放哪里、当前任务放哪里、运行状态放哪里、外部证据放哪里,最好分层清楚
重要
一旦信息混乱,模型很容易遗漏重点、忘记约束甚至自我污染
工具系统
Harness 的第二层职责,是让模型能够调用外部能力。但这并不是简单地把工具暴露给模型,而是要解决三个问题:
- 给它什么工具:根据任务需求和模型能力,选择合适的工具类型和数量,过多过少都不好
- 何时调用工具:设计合理的工具调用时机和触发条件,让模型知道在什么情况下应该调用工具,不需要查的时候别乱查,该查证的时候别硬答
- 工具结果如何反馈给模型:工具返回的结果是原封不动地塞回大模型,还是经过提炼、筛选,保持与任务的相关性
执行编排
Harness 的第三层职责,是让模型知道下一步做什么。一个完整的任务,应该有这样的编排:
- 理解目标
- 判断信息
- 基于结果进行分析,生成输出
- 检查输出,不满足要求就重新修正或重试
记忆和状态
Harness 的第四层职责,是让执行过程能够被记录和恢复。没有状态的 Agent 每一轮对话都像是失忆一样,之前说过的话、之前调用过的工具、之前得到的结果都没有了,模型只能依赖 Prompt 里有限的上下文来回忆,这对于多轮对话或者长流程任务来说是非常不友好的
核心要分清:
- 当前任务和状态
- 会话中的中间结果
- 长期记忆与偏好
评估与观测
这是最重要的一层职责,模型的输出、工具调用和最终结果都需要被验证、拦截、修正和回退。没有这一层的 Agent 就像是没有安全带的车,出了问题可能直接撞墙了
主要包括:
- 输出和验收
- 环境验证
- 自动测试
- 日志和指标
- 错误归因
约束、校验与失败恢复
在真实环境中,失败不是例外而是常态。如果没有恢复机制,Agent 出错就只能每次重头再来
主要包括:
- 约束:哪些能做,哪些不能做,明确边界
- 校验:对模型的输出和行为进行持续监控和验证,及时发现偏离预期的情况
- 恢复:失败后怎么重试、切换路径、回滚到稳定状态
Anthropic 的实践
Anthropic 在长程自主任务中总结了两个问题:
- 上下文焦虑
- 自评失真
上下文焦虑
随着任务的进行,模型需要处理的信息越来越多,尤其是当任务需要多轮对话、调用工具、处理外部信息时,模型很容易因为信息过载而出现 "上下文焦虑"。此时就会开始丢失细节、丢失重点,而且 Agent 好像自己知道要装不下了,就急于去进行收尾
很多系统面对这个问题的做法是将之前的上下文信息进行压缩。但 Anthropic 发现压缩可能是不够的,压缩只是变短了不代表那种负担感真的消失了
所以 Anthropic 的做法是直接引入了一个新的 Agent 来交接上一个 Agent 的工作
自评失真
如果让模型自己干活,最后让模型自己评价自己的话,那么模型往往会偏乐观。尤其是在设计体验、产品完整度这样没有标准答案的问题上
Anthropic 采用了一个 "分离" 的机制来解决这个问题,把干活的和验收的拆分:
- planner 负责把模糊的需求扩展成完整的规格
- generator 负责具体的代码实现
- evaluator 负责像 QA 一样去真实测试,不仅仅是抽象的进行审查,而是会落实到具体的交互,检查实际的结果
重要
生产和验收必须分离,只要评估者足够独立,系统就能形成一个真正有效的循环
OpenAI 的工程哲学
OpenAI 的思路是,工程师在这个环境中不需要写一行代码,只负责设计环境:
- 拆解任务:把产品目标拆分成 Agent 能理解的小任务
- 补充能力:在 Agent 失败时,不是让它 "再努力一些",而是直接询问 "环境中缺少了什么能力"
- 建立反馈链路:让 Agent 能看到自己工作的结果
渐进式披露
渐进式披露,指的是不要一开始就把所有信息都塞给 Agent,而是在它真正需要的时候,再把对应的信息交给它
这个思想和人读文档其实很像。我们不会一上来就把整个公司的工程规范、架构设计、接口文档、安全规则、质量标准全部背下来,而是先看目录,知道有哪些东西;等任务真的走到某一步,再打开对应的文档
对于 Agent 来说也是一样的。上下文窗口不是无限资源,它既是工作台,也是短期记忆。如果一开始就把所有规范都塞进去,表面上看是 "信息给全了",但实际上是在抢占模型真正思考和执行任务所需要的空间
早期错误:巨大的
AGENTS.mdOpenAI 早期在做 Agent 工程时,一个典型错误是把大量工程信息都塞进一个巨大的
AGENTS.md中这里面可能包括:
- 项目架构
- 代码规范
- 安全约束
- 测试要求
- 设计文档
- 质量评估标准
- 执行计划模板
这种做法的出发点是好的:希望 Agent 一开始就知道所有规则,避免遗漏重要上下文
但问题在于,Agent 并不会因为你给得多就理解得更好。相反,当所有内容都被压进同一个上下文里时,模型会很难判断哪些信息和当前任务真正相关
产生的结果:Agent 更糊涂了
巨大的
AGENTS.md会带来几个直接问题:- 上下文窗口被静态资料占满,真正用于当前任务的信息空间变小
- 不同层级的信息混在一起,模型无法判断哪些是硬约束,哪些只是参考材料
- 架构文档、设计文档、质量标准同时出现,模型容易平均用力,抓不住当前重点
- 每次任务都携带大量无关信息,推理成本变高,输出反而变得更不稳定
- Agent 看似"知道很多",但实际执行时更容易遗漏、误解或过早收敛
所以这个错误的本质不是"文档写得太多",而是文档进入上下文的时机和粒度错了。文档本身是资产,但如果不加选择地全部塞进上下文,它就会从资产变成噪音
后来的解决方式:目录先行,按需展开
更合理的方式,是把一个巨大的
AGENTS.md拆成多份小文档,并且让 Agent 先看到目录,而不是先看到全部内容。也就是说,第一层只告诉 Agent:- 这里有哪些能力
- 每份文档大概解决什么问题
- 什么情况下应该打开它
- 当前任务需要时,再读取对应细节
这样一来,Agent 的工作方式就从"背完整本手册"变成了"先看目录,再查章节"
和
skill的关系本质上就是渐进式披露的一种工程化实现。它不是把所有能力说明都一次性塞进主上下文,而是把能力封装成一个个独立模块
每个
skill通常只在入口处暴露少量信息,比如:- 这个 skill 解决什么问题
- 什么情况下应该使用它
- 入口文件在哪里
- 需要时再读取哪些附加资料、脚本或模板
当任务没有触发某个
skill时,它的详细内容不会进入上下文;只有当任务真的需要它时,Agent 才会打开对应的SKILL.md,再根据需要继续读取references、scripts、assets等内容所以
skill解决的不是"让 Agent 拥有更多文字",而是让 Agent 拥有一种更合理的信息加载机制
让 Agent 看见整个应用
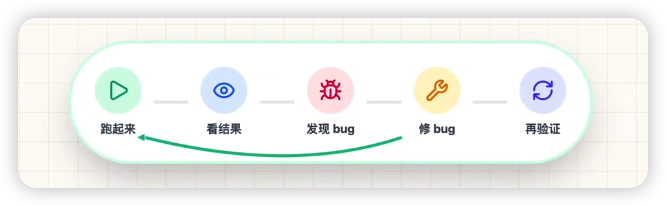
当代码产出速度一旦上来,瓶颈就不再是 "写",而是 "验"。验的步骤自然也交给了 Agent 来做。但这里的关键不是让 Agent 再读一遍代码,也不是让它自己在脑子里想象页面长什么样,而是要让它真正看到应用运行后的状态
也就是说,Agent 不能只停留在源码层面,它还需要进入运行时环境,像一个真实用户或者 QA 一样去检查结果
先把应用跑起来
代码能生成不代表应用能运行,所以第一步是让 Agent 有能力启动项目,并拿到真实运行环境
这通常包括:
- 安装依赖
- 启动开发服务
- 打开预览地址
- 捕获终端报错
- 识别构建失败、运行失败、热更新失败
再让 Agent 看见页面
对前端任务来说,页面结果不是代码本身,而是浏览器里的真实 UI。所以 Harness 要给 Agent 提供类似浏览器观察能力,让它可以看到:
- 页面是否白屏
- 布局是否错位
- 文案是否溢出
- 交互是否可点击
- 状态变化是否符合预期
- 移动端和桌面端是否都正常
让 Agent 按验收标准检查
只看到页面还不够,还必须知道按什么标准验。因此在任务开始时,最好把验收标准写清楚,比如:
- 页面必须能正常加载
- 主流程必须可点击
- 输入、提交、错误提示要符合预期
- 没有控制台错误
- 样式在关键断点下不能破
- 结果必须符合需求描述,而不是只要 "看起来差不多"
把错误反馈变成可修复信息
验证的目的是要把失败信息变成下一轮可执行的修复依据。一个好的 Harness 应该让 Agent 拿到这些反馈:
- 哪个页面失败
- 哪个交互失败
- 控制台报了什么错
- 网络请求是否失败
- 截图中哪里和预期不一致
- 失败更可能来自样式、状态、数据、路由还是接口
修复后必须回归
Agent 修完之后不能直接结束,而是要重新运行同一套验证流程
Agent 应用验证闭环
在后台管理系统中落地 Harness
假设现在要做的是一个后台管理系统,里面有列表、筛选、表单、详情、权限、审批流、导入导出、状态流转这些典型模块。通过 Harness 设计来落地一套适合后台系统的 Agent 任务执行和验收流程
核心思路
- OpenAI 负责告诉我们怎么设计环境
- Anthropic 负责提醒我们不要让同一个 Agent 自己干活又自己验收
- Skill 负责把能力模块化,按需加载
- Harness 负责把任务、上下文、工具、验证和恢复串成闭环
先建立项目级目录,而不是写一个巨大的说明文档
后台管理系统的信息非常多,如果全部塞进一个
AGENTS.md,Agent 很快就会进入上下文污染状态。所以第一步应该先建立一个轻量目录,让 Agent 先知道 "有什么",而不是一开始就知道 "全部细节"可以先这样拆:
.agent/ index.md product.md architecture.md routes.md api-contract.md permission.md ui-rules.md validation.md workflows/ user-management.md role-permission.md approval-flow.md import-export.mdindex.md只负责索引,不负责细节:# Agent 工作索引 - 做页面结构前,先读 `architecture.md` 和 `routes.md` - 做接口联调前,先读 `api-contract.md` - 做权限相关需求前,先读 `permission.md` - 做 UI 或交互前,先读 `ui-rules.md` - 做验收前,先读 `validation.md` - 做具体业务流时,再进入 `workflows/` 下对应文档这一步对应 OpenAI 的渐进式披露:先给目录,再按需展开
把后台系统的能力封装成
skill后台管理系统的需求看似很多,但高频能力其实是固定的,比如建列表页、建表单页、接权限、写校验、跑验收,可以把它们拆成几个
skill:skills/ admin-list-page/ SKILL.md admin-form-page/ SKILL.md permission-guard/ SKILL.md api-integration/ SKILL.md admin-validation/ SKILL.md例如
admin-list-page/SKILL.md不需要写完整项目知识,只写触发条件和执行方法:# admin-list-page 当任务涉及后台列表页、筛选区、表格列、分页、批量操作时使用 执行前读取: - `.agent/ui-rules.md` - `.agent/api-contract.md` - 对应 `workflows/*.md` 输出要求: - 列表查询参数必须可回显 - loading、empty、error 状态必须完整 - 操作按钮必须考虑权限 - 分页、筛选、重置、刷新必须可用这样 Agent 不需要一开始读完所有后台规则,而是在做列表页时才加载列表相关能力
按 Anthropic 的方式拆分角色
后台管理系统最容易出问题的地方,是同一个 Agent 既负责写代码,又负责说自己写得没问题。Anthropic 的经验是生产和验收要分离,所以至少要拆成三个角色:
- Planner:把需求拆成页面、接口、权限、状态、验收标准
- Builder:根据计划写代码,只负责实现
- Evaluator:像 QA 一样验收应用,不替 Builder 找借口
一个实际任务可以这样流转:
这里最关键的是 Evaluator 必须独立。它不能只问代码有没有写,而是要真的打开页面、操作流程、检查错误状态。但这个拆分不是简单地开三个聊天窗口,而是需要一个主线程来调度它们。主线程也可以理解成 Orchestrator,它不负责具体写代码,而是负责保存任务状态、传递上下文和决定下一步该交给谁
Orchestrator -> 调 Planner 产出任务规格和验收清单 -> 调 Builder 根据规格实现 -> 调 Evaluator 根据验收清单检查应用 -> 如果失败,把失败报告交回 Builder -> 如果通过,结束任务所以实际落地时可以先有三种形态:
- 单 Agent 分阶段执行:同一个 Agent 先当 Planner,再当 Builder,最后切换成 Evaluator
- 多 Agent 并行或串行执行:主线程分别启动 Planner、Builder、Evaluator 三个上下文
- 自动化脚本接管部分 Evaluator:用 Playwright、Vitest、接口测试来提供客观证据,Agent 只负责解释和判断
给 Agent 一套后台系统专用验收清单
后台系统不是看起来有页面就算完成,它一定要验流程。验收清单不是 Evaluator 临时想出来的,而是 Planner 在任务开始时就应该产出的。主线程保存这份清单,然后在验收阶段交给 Evaluator
Evaluator 接收到的上下文应该包括:
- 任务规格
- 验收清单
- 应用启动方式
- 页面路由
- 测试账号
- 允许使用的工具
- 输出报告格式
可以给 Evaluator 固定一份
validation.md:# 后台管理系统验收清单 ## 页面加载 - 页面可以正常进入 - 没有白屏 - 没有控制台错误 ## 查询列表 - 初始列表能加载 - 筛选条件能生效 - 重置后能恢复默认查询 - 分页能正常切换 ## 表单操作 - 必填项校验生效 - 编辑时数据能正确回显 - 提交成功后有反馈 - 提交失败后能展示错误 ## 权限控制 - 无权限按钮不可见或不可点击 - 越权访问能被拦截 - 不同角色看到的操作入口不同 ## 异常状态 - loading 状态存在 - empty 状态存在 - error 状态存在 - 接口失败后可重试Evaluator 的提示可以这样写:
你现在是 Evaluator,只负责验收,不允许修改代码 请根据下面的验收清单检查应用: - 页面路径:/system/role - 启动命令:pnpm dev - 测试账号:admin / 123456 - 验收清单:见 validation.md 你必须实际打开页面、观察结果、检查控制台和网络请求 如果失败,输出结构化失败报告 如果通过,输出验收通过报告重要
Evaluator 不允许修改代码。它只负责验收,否则它就会一边验一边替 Builder 修,角色边界又混在一起了
让 Agent 真的看到应用
对后台管理系统来说,必须让 Agent 进入运行时环境。只读代码是不够的,因为很多问题只有页面运行起来才能看到
Harness 应该提供这些观察能力:
- 启动前端服务
- 打开指定路由
- 截图当前页面
- 读取控制台错误
- 观察网络请求
- 点击按钮、输入表单、切换分页
- 对比页面状态是否符合验收清单
对后台系统来说,一个典型验收流程应该是这样:
打开 /system/role -> 等待列表加载 -> 输入角色名称筛选 -> 点击查询 -> 检查表格结果 -> 点击新增 -> 提交空表单 -> 检查必填校验 -> 填写合法数据 -> 提交 -> 检查成功反馈和列表刷新这里的点击、输入、切换分页,最好不是人来手动点,而是 Agent 通过浏览器自动化工具来执行。最常见的是 Playwright:
Playwright 示例import { chromium } from 'playwright'; const browser = await chromium.launch(); const page = await browser.newPage(); await page.goto('http://localhost:5173/system/role'); await page.getByPlaceholder('请输入角色名称').fill('管理员'); await page.getByRole('button', { name: '查询' }).click(); await page.getByRole('button', { name: '新增' }).click(); await page.getByRole('button', { name: '确定' }).click();监听控制台错误const consoleErrors: string[] = []; page.on('console', (msg) => { if (msg.type() === 'error') { consoleErrors.push(msg.text()); } }); page.on('pageerror', (error) => { consoleErrors.push(error.message); });监听网络请求const failedRequests: string[] = []; page.on('response', async (response) => { const status = response.status(); if (status >= 400) { failedRequests.push(`${status} ${response.url()}`); } }); page.on('requestfailed', (request) => { failedRequests.push(`FAILED ${request.url()} ${request.failure()?.errorText}`); });把失败变成结构化反馈
如果验收失败,Evaluator 不应该只说 "失败了",而是要输出 Builder 能直接执行的修复报告
可以要求失败报告固定成这样:
# 验收失败报告 ## 失败页面 `/system/role` ## 失败步骤 点击新增后提交空表单 ## 预期结果 角色名称、角色编码出现必填校验 ## 实际结果 表单直接提交,没有展示校验提示 ## 可能原因 表单 rules 未绑定或字段 prop 不一致 ## 修复建议 检查 `RoleForm.vue` 中 `el-form-item` 的 `prop` 是否和 rules 字段一致这就是 Harness 的价值:把失败从一句模糊评价,变成下一轮可执行的修复输入。失败报告应该先交给主线程,而不是直接交给 Builder
主线程要判断:
- 这个失败是不是阻塞问题
- 是不是需要 Builder 修
- 是不是验收标准本身有问题
- 是否需要 Planner 重新拆规格
- 是否允许进入下一轮
只有主线程确认这是实现问题后,才把失败报告交回 Builder,并且要求 Builder 只修报告里的失败项,不要扩大修改范围
建立任务结束条件
后台系统的 Agent 任务不能只以 "代码写完" 作为结束条件,而应该以 "验收通过" 作为结束条件
结束条件也不是最后才告诉 Evaluator,而是 Planner 在任务开始时就要定义出来,并由主线程保存
一个任务可以设置成:
- 代码实现完成
- 类型检查通过
- 单元测试或基础检查通过
- 页面能启动
- 核心流程人工模拟通过
- Evaluator 没有阻塞问题
- 失败报告为空或只剩低风险问题
最终的 Harness
落地到后台管理系统里,Harness 最终应该长成这样: